[Date Prev][Date Next] [Thread Prev][Thread Next] [Thread Index] [Date Index] [Author Index]
Printing and weird (non-latin0 ;-) ) charsets -- summary
- From: Cyrille Chepelov <cyrille chepelov org>
- To: dia-list gnome org
- Subject: Printing and weird (non-latin0 ;-) ) charsets -- summary
- Date: Wed, 29 May 2002 01:32:22 +0200
Hello all,
I've been banging my head over the Postscript problem for a couple hours
now.
Here's a semi-raw log of my conclusions:
=============================================================================
There are two problems:
* (Encoding problem) telling the Postscript interpreter what
Unicode Character we're talking about
* (Font Matching problem) telling the Postscript interpreter
what Glyph (graphic character representation) we're talking
about, or how to find a default glyph if current font doesn't have
one.
We attempt to solve the first problem in lib/ps-utf8.c, by building
custom encoding maps, lazily re-encoding the fonts according to these
maps, and then switching between re-encoded fonts (this is why text in
dia Postscript output always looks like line noise, even for English).
We almost don't attempt to solve the second problem. As a stop-gap
solution, Akira TAGOH made dia select Ryumin-Light instead of Courier
using the gettext() subsystem when the locale is Japanese, but this is
not the right solution (nor this has been intended to be).
----
One of the problems of CJK support is that for a single Unicode
character, there may be more than one graphical representation;
depending on the actual language used, different graphical
representations may be sought.
Well this paragraph is stupid: one can say the same for the Roman
writing system.
----
Zhang Lin-bo noticed that in the zh_CN locale (Mainland China, using
the Simplified Chinese writing system), and as of 0.90.rc2, dia's EPS
output is not usable by his Ghostscript.
He proposed a simple patch, which bypassed the PS-Unicoder re-encoding
and simply output UTF-8 strings. This worked on his Ghostscript;
however, this broke Western (latin0) text output on a non-UTF8 patched
Ghostscript.
----
I thought for a while of using the <1234> string representation to
solve the unicode problem. That will not work.
----
It *seems* that using the CMap feature of Postscript, there could be a
way to output UTF-8. However, CID-keyed fonts look somewhat horrible
to setup.
Well. If you install gs-aladdin on Debian, you die. If you install
only the Free gs, you have all the stuff working. I love defoma.
----
OK, assuming a properly CJK-enabled Ghostscript, it *is* possible to
have it eat a UCS2 or UTF8 stream. That stream will probably not be
accepted by a crude Postscript device. However, ps2ps output will
include the fonts and all stuff and will be kosher Postscript.
----
PS-Unicoder is working well for latin0, latin1 and latin2. Not sure
for KOI8-R. It is also working well for at least a subset of Japanese
needs, when the locale is Japanese.
----
Proposal for the complete solution:
===================================
We need a text file, which describes for each font the Unicode range
it is known to support (roughly), and the output method.
Output method can be:
PSU (using the dia PS-Unicoder)
UTF-8 (exporting a crude UTF-8 stream)
UCS-2 (exporting an UCS-2 stream) (not sure if needed with UTF-8)
The non-PSU method would work with non-CID-keyed fonts only. CID-keyed
fonts would require the use of UTF-8 (or UCS-2, but UTF-8 can express UCS-4)
Example:
Courier: PSU 0000-052F, 1E00-218F
BousungEG-Light-GB-UniGB-UTF8-H: UTF-8 2E80-303F, 3200-9FFF
Ryumin-Light: PSU 3040-30FF
Helvetica PSU: 0000-052F, 1E00-218F
GBZenKai-Medium-UniGB-UTF8-H: UTF-8 2E80-303F, 3200-9FFF
GothicBBB-Medium: PSU 3040-30FF
Symbol: PSU 2190-2E79
(of course, dia would search for this file in /usr/lib/dia and in ~/.dia).
When presented with some Unicode text to be rendered in some font,
currently dia "almost" ignores the font and just builds an encoding
map (in fact, it builds encoding maps, and then builds re-encoded
fonts for each encoding maps).
What it would do in the future: the text file described above would be
treated as a circular list of fonts. For each character, if the
current font does not claim to handle the current character, then the
next font is considered (until one font has found the right character
or we looped over the whole list).
Example:
we have one string with the following contents
'Hello "Han""Zi" world "smiley" "Aleph"'
(with "Han" and "smiley" being the Unicode characters), and we want to
print it as Courier.
'Hello ' can be represented by Courier (they all fall inside
0000-052F).
'"Han"' can't. So we start searching in the list. Next after Courier
is Bousung. It can display "Han". So we use this to display "Han". And
now we fall back to Courier.
'"Zi"' can't be displayed by Courier, but it can be displayed by
Bousung. So we use this font too.
etc.
"smiley" can only be represented by Symbol, so after testing the
others, we'll fall to that one.
No font claims to be able to represent "aleph". So, after testing all
fonts, we'll go back to Courier and attempt to represent "aleph" using
Courier (this will probably fail)
It is very probable that this fontsubst file will have to exist in at
least four versions, with Japanese, Simplified Chinese, Traditional
Chinese and Korean slants. However, the users and the distributors
will have a very serious ability to tweak the settings without
resorting to patching the code (and we remove the
font-selection-via-gettext)
We can safely ignore the issue of embedding fonts into the Postscript
output: ps2ps can handle that much better than we can. It'll sanitise
our output for processing by Level 1 printers.
To check: whether Pango does not already provide something similar
usable for printing.
Damn. pango_font_get_coverage() is lovely.
(that doesn't override the basic algorithm; however, we'll have the
ability to make a smarter choice of fallback fonts when we can ask
Pango whether that particular fallback is a good idea or not. We'll
probably be able to get rid of that fontsubst file, but we'll have to
add a language attribute to the Text objects.).
Yes, that means ZLB's patch will get in in some form...
=============================================================================
I've now been able to read the EPS files as sent by Zhang Lin-bo with no
modifications or no tweaking on my system, and have them render properly
(yay !)
(to do that, I had to remove gs-aladdin, and add gs-aladdin,
ttf-arphic-gbsn00lp ttf-arphic-gkai00mp gs-cjk-resource and defoma
to my sid system. Once this is done, things are running automagically).
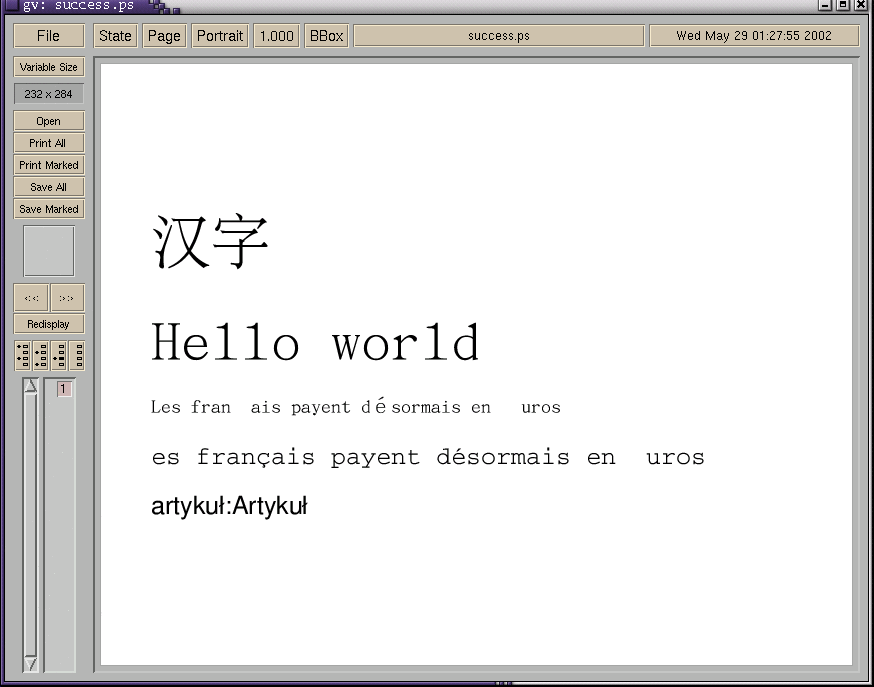
The attached file here renders "correctly" (modulo /Euro ) on my system. It
also demonstrates the ability to mix UTF-8 CID fonts and PS-Unicoder classic
fonts. Finally, it proves I didn't break support for latin2 ;-)
I would love comments on this. None of this message will have immediate
impact, but I plan to do this for 0.91.
-- Cyrille
--
Grumpf.
{kind=link}
- Follow-Ups:
- Re: Printing and weird (non-latin0 ;-) ) charsets -- summary
- From: Zhang Lin-bo
- Re: Printing and weird (non-latin0 ;-) ) charsets -- summary
[Date Prev][Date Next] [Thread Prev][Thread Next] [Thread Index] [Date Index] [Author Index] Mail converted by Mofo Magic and the Flying D
Other Directory Sites: SeekWonder | Directory Owners Forum